

Routing - A Delusion among developers
Senior Development Team Lead - GUVI
It’s been always confusion among developers when it comes to what people want to see in their URL address bar as https://www.hackerkid.org/turtle/1/take-right-then-left looks better compared to https://www.hackerkid.org/turtle?questionId=1&questionName=take-right-then-left, especially for pages where the page contents are dynamic. The first URL is what SEO guys want from a developer, but for developers, it will be additional work and often leads to confusion as there are different approaches available for achieving similar results.

Routing Approaches:
- Static Files
- Server Side Routing
- Client-Side Routing
Static Files
Back in the days when JavaScript is not in pictures and web pages are just static HTML pages, everything is straightforward as each page is basically a separate HTML file like about.html, contact.html, and so on.
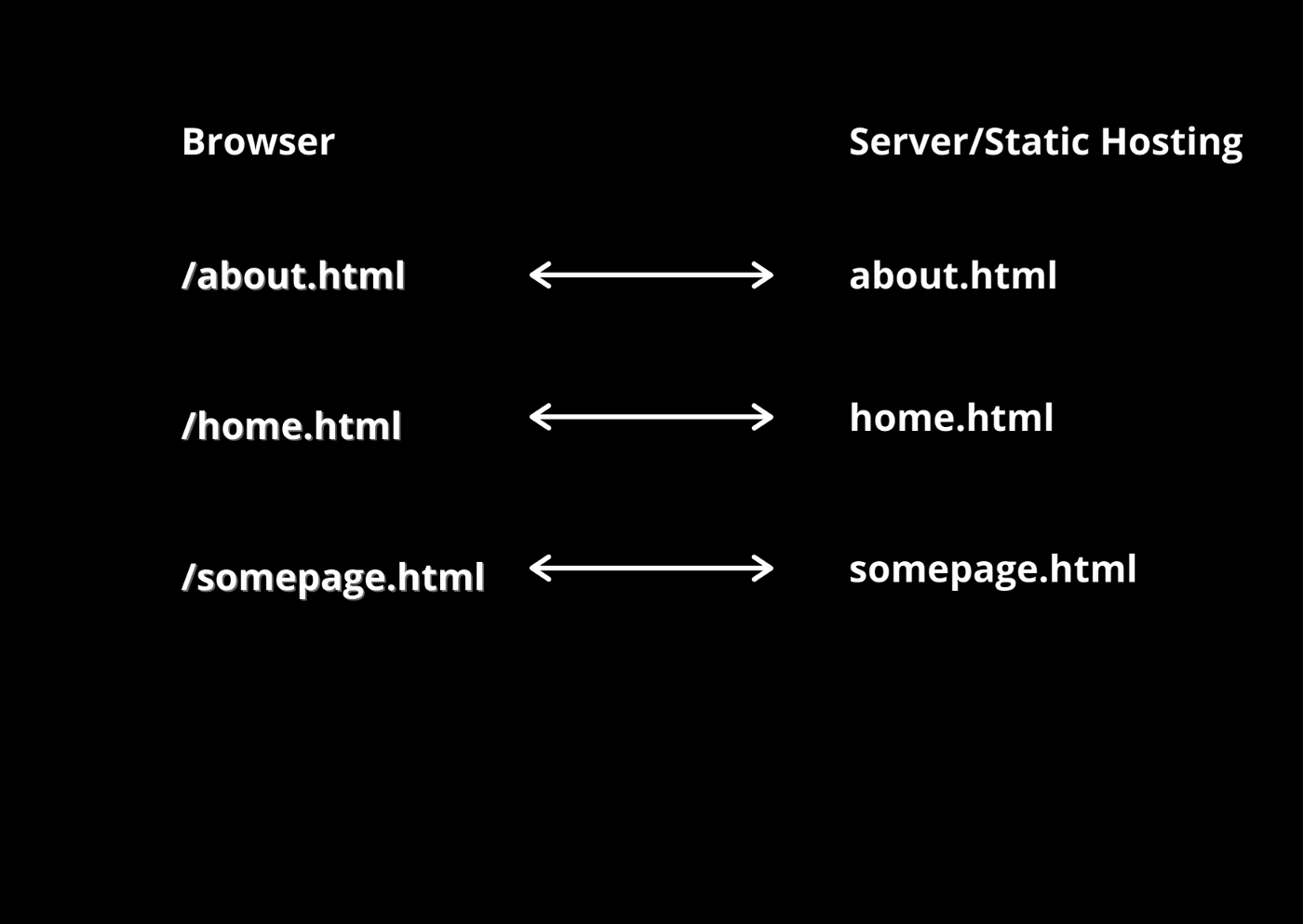
But with time, both the number and complexity of the webpages grew and it became a headache for developers to develop and maintain such a huge codebase of HTML files. Just think of making some changes to the header and footer of all the HTML pages!
With the disadvantages aside static file routing is still a better option in modern days in terms of performance compared to the client and server-rendered pages. Not buying my statement? look at all these static site generators, they all exist for a reason Gatsby, Eleventy, and more. With these static site generators, the development and maintainability aspects of static sites are made much easier.
Server Side Routing
When JavaScript came into the picture lot of things changed as it provided more control over the contents of the page with the ability to change page contents dynamically. Developers made use of query strings to dynamically load different kinds of page contents using a single page that had the same page structures so the URLs looked like https://www.hackerkid.org/turtle?questionId=1&questionName=take-right-then-left. Here a single page named /turtle had different kinds of page contents based on the query parameters supplied. This was fine but not the best in terms of SEO and user perception.
So in order to make URLs look something similar to https://www.hackerkid.org/turtle/1/take-right-then-left server-side routing came into the picture. Since servers offered a way to rewrite, redirect and serve resources based on routes. In server, we can actually do something similar to the below to achieve the above URL structure(syntax totally depends on the server you are using can be apache, Nginx, and others).
RewriteRule ^turtle/(.*) /turtle.html [NC,L]
Now, with the above configurations, all requests matching /turtle/ will be served with turtle.html. Once the page loads, JavaScript makes use of the information available in the URL such as /turtle// to render the page contents and even can redirect to appropriate page if the link has invalid or incorrect information.
With help of this developers even removed extensions such as .html, and .php from their pages as it's definitely unnecessary information presented to the users. Below server rewrite configuration removes .html and .php extensions from URLs.
RewriteCond %{THE_REQUEST} /([^.]+)\.(html|php) [NC]
RewriteRule ^ /%1 [NC,L,R=301]
The downside of server-side routing is front end developers need to depend on backend/server guys who have access to the server to make this change whenever a new dynamic route needs to be configured and also need to ensure that the server configuration is changed prior to the update that depends on it.
Another downside will be, that the whole page needs to be reloaded each time even for pages like https://www.hackerkid.org/turtle/1/take-right-then-left and https://www.hackerkid.org/turtle/2/draw-a-circle where only the contents are going to change which leads to additional server request to get assets needed to render the page, though cache may come action users are going to see white screens often while the page is loading. Definitely, we can do better right? That's where client-side routing comes to the rescue.
Client-Side Routing
Too tired already? Check this page to have a quick glimpse of client-side routing in action before we continue https://johnpremkumar.github.io/routing-demo/
In client-side routing, all the routes are managed from client-side JavaScript and the server is configured to serve a single HTML page irrespective of the request. The server configuration for maintaining routes on the client-side should look something like the below where the HTML file name is index.html(most commonly used) but it can be of any name.
RewriteRule ^ /index.html [NC,L]
Now, whatever the page we visit under a domain, it can be /about, /contact, /some/random/route the response from the server will be your /index.html. The JavaScript loaded via /index.html will contain all the route information thus appropriate information is shown to users according to the URL and even 404 pages can be shown if the URL is not configured in client-side routes. Check the below image for a clear understanding.
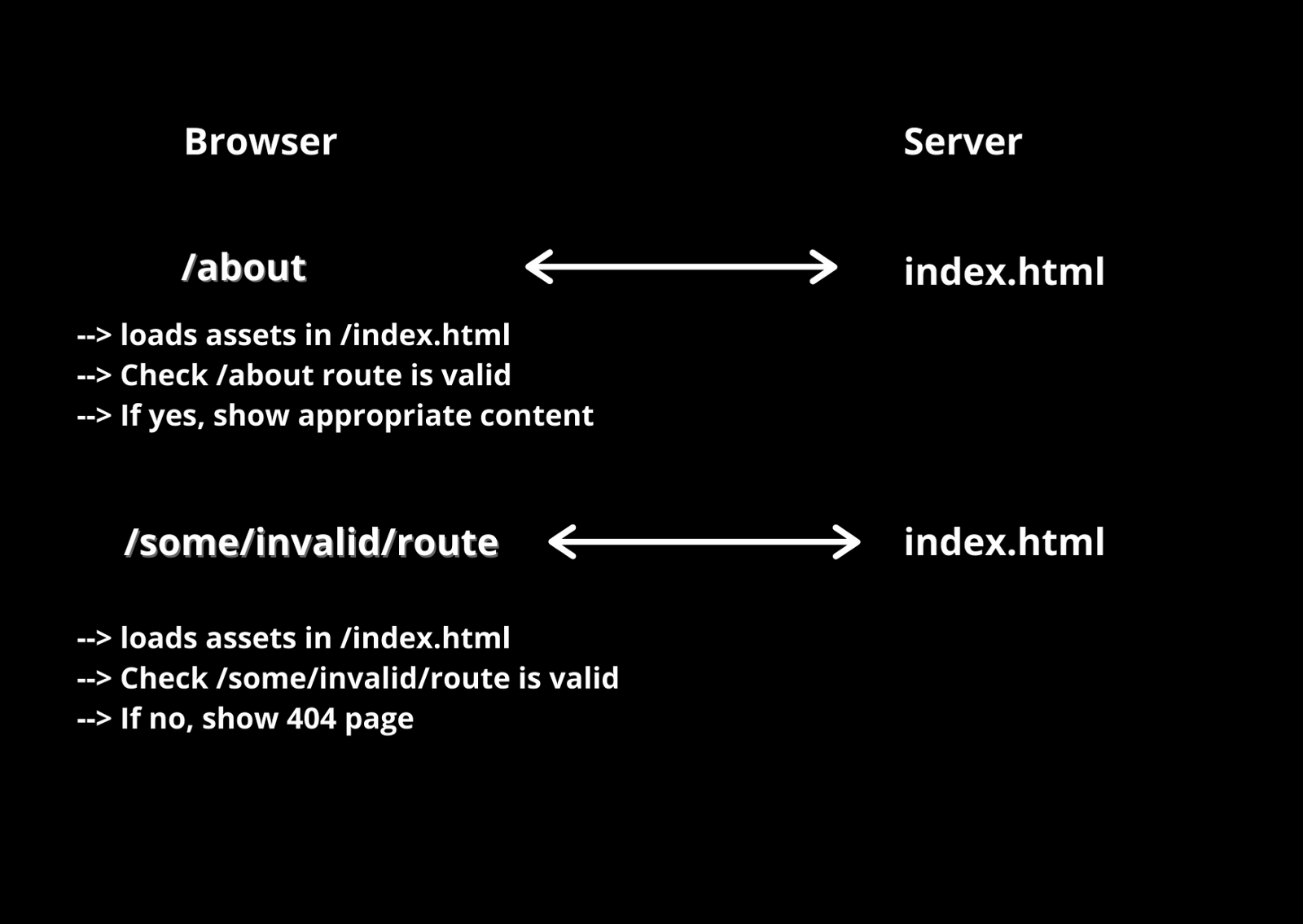
The client-side routing is made possible because of History API checkout more about it here in the MDN Docs.
Even with all the good things client-side routing has to offer in terms of managing routes. It still has some downsides in terms of performance as the entire page is loaded via JavaScript your page visitors must be seeing a loading animation for some time. Now that's something about rendering rather than routing right? Maybe I can write about it in detail in my next post.
Not so fast! have you guys forgotten about this URL https://www.hackerkid.org/turtle#/1/take-right-then-left which is kind of similar to query parameters but makes use of hash to perform routing, it is also an approach in client-side routing known as hash-based routing. Maybe you guys can check more about it if you are interested.
Feel free to post your comments!